Object Detection and Segmentation using different Backbone Architectures and training Datasets
Team Members: Srikanth Kilaru, Michael Wiznitzer, Solomon Wiznitzer
Northwestern University ME 349: Machine Learning (Spring 2018)
Abstract
Object detection is the process of finding instances of real-world objects such as people, cars, bicycles, and buildings in images or videos. Object detection algorithms typically use extracted features and learning algorithms to recognize instances of an object category. Object detection is commonly used in applications such as image retrieval, robotics, security, surveillance, and advanced driver assistance systems (ADAS). Object detection and segmentation is an area of significant R&D activity in both academia and industry. Facebook AI Research (FAIR) Labs open sourced their latest object detection and segmentation algorithm, code named Detectron, in the interest of attracting more users and contributors for these algorithms.
Task
We leveraged the modular nature of the Detectron code base to replace the default backbone from ResNet50 / ResNet101 to a backbone that is not already provided in their ‘model zoo’. We added a new backbone, the Google Inception_ResNet_v2 CNN to the model zoo, which was implemented in python utilizing Caffe2, and tested the object detection and segmentation capabilities of the model when trained on the PASCAL VOC 2012 & MS COCO dataset. Inference produces images that are overlaid with segmentation mask and bounding box of the object instances along with their classification and associated confidence level.

Example 1: Detectron+Inception output has low confidence of person but detects it anyway. Low confidence is probably due to person's keypoints are almost blended with motorcycle and the segment mask seems to fit the the typical human frame starting from head/helmet down.
Results
Detectron with Inception as a backbone did not perform as well as with Resnet. Some of the images could not be infered at all, even incorrectly, after lowering the detection threshold for bounding boxes, from a default of 0.7 to 0.3. In addition, the lack of the FPN feature (please see detailed report) in our testing could have contributed to the low accuracy of the inference. Please see sample results from inference below. For a more complete list of inferences based on Inception model, please see the inception-inference-coco folder.
Further background and Detailed Report
Deep Learning (CNN) architectures such as AlexNet, VGG, Resnet and Inception have proven to be very successful in image classification tasks. However they were not particularly useful for object detection. A key advance in the area of object detection and segmentation has been the work done by some researchers who now work at Facebook.
To increase the accuracy and performance of object detection algorithms, these researchers, introduced a Region of Interest (ROI) Proposal Network (RPN) that shares full-image convolutional features with the main detection network (also refered to as the ‘backbone’), thus enabling nearly cost-free region proposals. An RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position. The RPN is trained end-to-end to generate high-quality region proposals, and then merge the RPN and CNN into a single network by sharing their convolutional features. The RPN portion tells the unified network where to look.
A further enhancement made in the last 18 months was the development of the FPN. Feature pyramids are a basic component in recognition systems for detecting objects at different scales. But many deep learning object detectors have avoided pyramid representations, in part because they are compute and memory intensive. But the FAIR team exploits the inherent multi-scale pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost. A top down architecture with lateral connections is developed for building high-level semantic feature maps at all scales. This architecture is called a Feature Pyramid Network (FPN), and it has shown significant improvement as a generic feature extractor in several applications.
The modular nature of the Detectron code base enabled us to replace the default backbone from ResNet50 / ResNet101 to a VGG or any other backbone that is not already provided in their ‘model zoo’. We added a new backbone, the Google Inception_ResNet_v2 to the model zoo. The way the FPN feature part of Detectron is currently developed, it makes it extremely challenging to plugin non-ResNet models(like VGG and Inception) to the FPN. Hence we had to turn off the FPN feature when testing the Inception module. Our results show that with a new previously untested backbone and with the FPN off, the object detection capabilities of the model when trained on the MS COCO dataset and PASCAL VOC 2012 is marginal. Please see the below table for the Mean Average Precision when Inception was trained and validated on the COCO dataset using the rules of the COCO website.
Here is a list of files added and changed in the Detectron code base -
-
8 GPU version of the config YAML file ml349_2gpu_e2e_faster_rcnn_Inception_ResNetv2.yaml
-
8 GPU version of the config YAML file ml349_8gpu_e2e_faster_rcnn_Inception_ResNetv2.yaml
-
Main file with Inception Conv layers Inception_ResNetv2.py
-
Code that calls the function to add Inception Conv layersmodel_builder.py
-
For your own inference you can download the weights trained using Inception on COCO dataset - inception_coco_model_final.pkl
Some sample images with object detection and segmentation working correctly when Detectron uses the Inception backbone and is trained on the MS COCO dataset -

Example 2: Detectron+Inception output showing persons and a car

Example 3: Detectron+Inception output showing several persons on the deck but misses the boats
Some sample images with object detection and segmentation NOT working correctly when Detectron uses the Inception backbone and is trained on the MS COCO dataset -
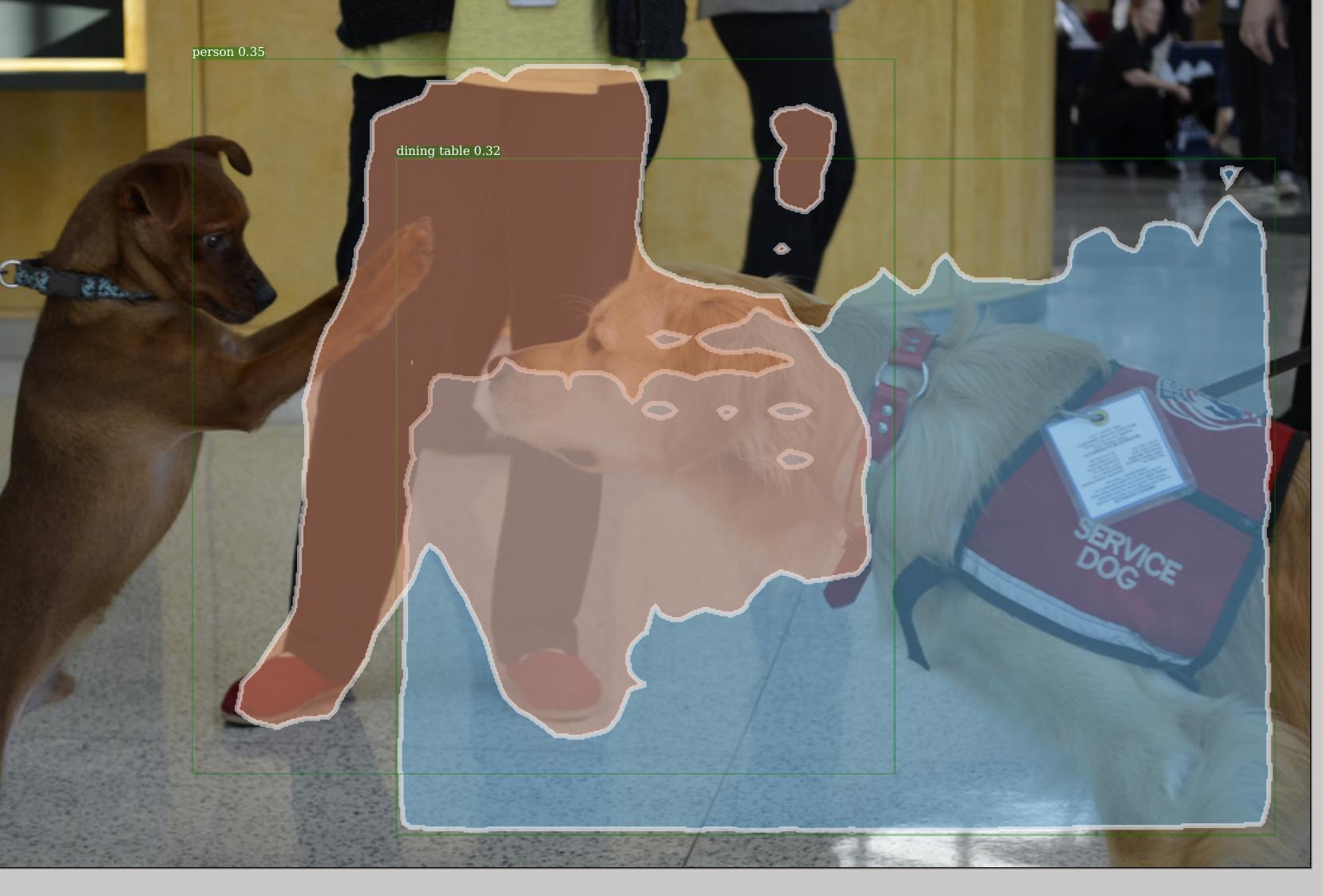
Example 4: Detectron+Inception output with poor detection. It however detects the lower part of the person
Some sample images with object detection and segmentation working very marginally or missing detection of significant (number of) objects in the image -

Example 5: Detectron+Inception output missing several key points including people, automobiles and cycles. It gets a portion of the motorcycle right
Future Work
This project exposed us to the inner working of how world class CNNs are actually implemented especially using Deep Learning frameworks for GPU enabled machines like Caffe. If time permitting, in the future we would like to rewrite the interface between FPN and non-ResNet backbones so that it is much easier to plug in these backbones without giving up FPN functionality. This would enable us to do a fair comaprison with the results published by the FAIR team.
Primary Areas of contribution
Srikanth Kilaru - Adding Inception backbone to Detectron
Setup and Installation Instructions
Setting up the GPU enabled VM on Google Cloud Platform (GCP)
One of the requirements of Detectron is to use a machine with NVIDIA GPUs. To gain access to this resource, we each created free accounts on Google Cloud using our personal email addresses and credit cards. Unfortunately, the free version (although it does give $300 credit for the first year) does not allow access to GPUs so we upgraded our accounts, albeit at no up front charge. We then followed the instructions here to get access to 8 up to K80 GPUs.
After creating a project, we then made a VM Instance with the following settings:
- Zone: us-central or us-west
- Machine type:
- Cores: 4 vCPUs
- Memory: 20 GB memory
- GPU: 1,2, or 8 K80 GPUS
- Boot Disk:
- OS Image: Ubuntu 16.04 LTS
- Boot Disk Type: Standard persistent disk
- Size: 500 GB
- Firewalls - Allow HTTP and HTTPS traffic
Note: During the course of the project, we used either 1, 2, or 8 GPU K80s for model training. Addtionally, we chose to use Ubuntu Linux 16.04 as the OS image since all of us are familiar with it. Finally, we decided to use a standard persistent disk with 500 GB storage since this was cheaper than a solid-state drive and would be able to store the PASCAL VOC image dataset as well as the COCO dataset.
Finally, we installed the Google Cloud SDK on our local machines and followed the instructions here so that we could copy files (specifically classified/inferred images) from the VM to our laptops.
Detectron
After booting up the VM instance, we followed the directions outlined in Detectron’s repo to install Caffe2 from source, some standard Python packages, and the COCO API. During installation, we found (after countless hours of debugging) some issues that we fixed as follows:
- In the ‘Install Dependencies’ section on the Caffe2 ‘Install’ page, we added
python-setuptoolsto thesudo apt-get installcommand. - In the ‘Install cuDNN (all Ubuntu versions) section on the Caffe2 ‘Install’ page, instead of registering to get the Version 6.0, we just switched all appearances of
v5.1in the gray command window tov6.0which worked just fine. - When doing the
sudo make installin the ‘Clone & Build’ section of the Caffe2 ‘Install’ page, we added the flag-DUSE_MPI=OFFso that the final command wassudo make install -DUSE_MPI=OFF. - After the installation (which took a little over an hour), but before checking to see if the Caffe2 installation was successful, we edited the
bash.rcfile to update thePYTHONPATHenvironment variable toexport PYTHONPATH="/home/<user>/pytorch/build/"
The above tweaks took many hours to figure out but once completed, the check to determine whether or not Caffe2 installed properly outputted ‘Success’.
VNCServer
In order to easily browse the internet for image datasets and look through the Home Folder, we installed a VNCserver by following the instructions here. For clients, we just installed any VNC client like the Remmina Remote desktop client, VNCViewer, or KRDC.
Also, we made a firewall rule in the GCP to allow communication between the server and the client as outlined in the ‘Open the firewall’ section here.
Initial Test
For fun, we tested a pretrained Mask R-CNN model using a ResNet-101-FPN backbone on some test images provided by Detectron as well as an image we randomly found online. We ran the code shown under option 1 here. The result which correctly classified a number of people, a tie, a car, and a chair can be seen below.

Backbone Exploration
One of our main goals was to investigate the effect of using various backbone network architectures during training and see how the Average Precision values are reflected based off of that. The backbones utilized in this project include both existing ones in the Detectron package as well as the Google Inception backbone mentioned above. The are listed below:
- Resnet 50 with FPN head
- Resnet 50 with C4 head
- Resnet 101 with FPN head
- VGG16
- VGG_CNN_M_1024
- Google Inception_Resnet_v2
Dataset Acquisition
The original goal was to test these backbones on the Open Images V4 dataset which boasts:
- Over 19,500 classes of objects
- Over 9 million annoated images
- 5.65 million training images
- 41,620 validation images
- 125,436 testing images
This is by far a much bigger dataset with many more categories than the COCO dataset which Detectron uses for their models. Furthermore, the current Detectron algorithm has already been evaluated on the COCO, PASCAL VOC, and ILSVRC datasets, so training it on Google’s Open Image’s dataset would be a novel idea to explore.
In order to accomplish this, we needed to get Open Image’s annotation files to be in the right format - specifically COCO’s JSON format. This proved to be rather difficult since Open Image’s annotations are in csv format and are annotated differently than COCO’s. Furthermre, after spending much time following a tutorial to convert the annotation files into JSON format, we learned that one - the JSON files we obtained were still not in COCO’s JSON format, and two - that we also had to watch out for corrupted or missing image/annotation files. It was at this point where we decided to try working with a different dataset that fits COCO’s annotation format.
We briefly investigated using the Cityscapes
Resnet vs. VGG vs. Inception
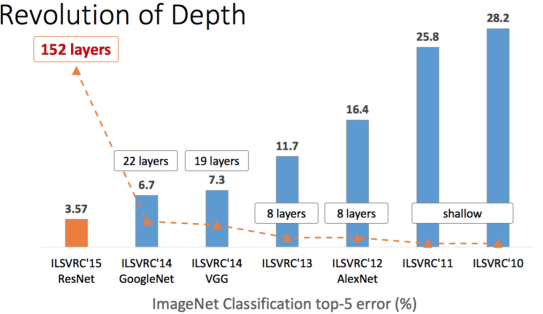
From the Deep Residual Learning for Image Recognition paper by Kaiming He, et al, the authors describe that in theory, a neural network should have reduced training error as the number of layers inrease. This is because increased depth enables the network more opportunity to learn complex features. While this is true to a certain extent (VGG16 outperforms an AlexNet due to having multiple layers of 3x3 convolution filters), it is not completely accurate. Rather, a ‘plain’ network (similar to VGG) tends to increase in training error if the number of layers is too big. In contrast, training error continues to decrease as the number of layers increase by ResNet. To achieve this, a ‘shortcut’ is created between an input to a hidden layer and right before an output a second layer down (as shown in the image below).
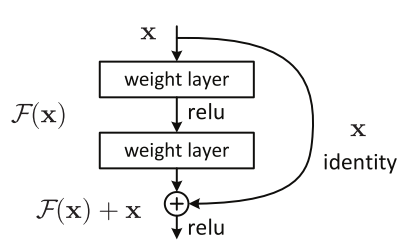

Not only does this address the vanishing gradient issue to a certain extent (since an output layer will at the very least be equal to its previous residual), it also allows the network to set weights to equal zero if the residual is optimal or set the weights to find small fluctations around the residual (a.k.a the identity). Furthermore, at the 2016 Conference on Computer Vision and Pattern Recognition (CVPR), He showed that as the layers of ResNets increased, the percent error on the ImageNet dataset decreased (figure above to the right). Thus, it would be logical to assume that for the 5 different backbones mentioned above, ResNet-101 should be a bit better than ResNet-50, which should outperform Inception which should beat VGG_M_CNN_1024, leaving VGG_16 in last place.
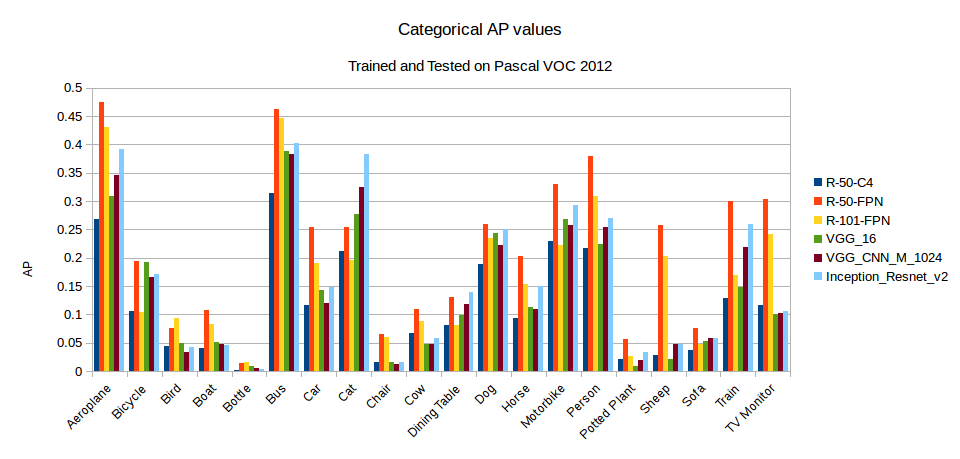
From the data shown above, this trend can be clearly seen to a certain extent. Both ResNet-50-FPN and ResNet-101-FPN are higher than the other backbones. Inception is in third placed followed by the two VGGs in the order we predicted. Furthermore, the ResNet-50-C4 backbone (called ‘C4’ as features were extracted from the final convolutional layer of the 4th stage) ranked the least among the ResNet models according to the Mask R-CNN paper by Kaiming He, et al which can be seen in the plot above as well. The only oddity is that ResNet-101-FPN is not higher than ResNet-50_FPN. Perhaps, if the models had more time to train, this phenomenon would not have occured.